
#1
- 별칭붙히기
1. SELECT 컬럼명 별칭, 컬럼명2 별칭 FROM 테이블이름;
2. SELECT 컬럼명 AS 별칭, 컬럼명2 AS 별칭 FROM 테이블이름;
3. SELECT 컬럼명 "별칭", 컬럼명2 “별칭” FROM 테이블이름;칼럼은 as 다른건 띄어서
큰따옴표는 쓰지않는걸 권함 코드쓸때 헷갈리고 귀찮음
- SHOW user 하면 어떻게 접속했는지 알 수 있다
USER이(가) "TEST01"입니다.
- DESC emp;
이름 널? 유형
-------- -------- ------------
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
지정한 이름과 유형을 알수있음
- SELECT job FROM emp;
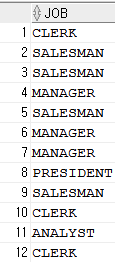
- SELECT DISTINCT job FROM emp;
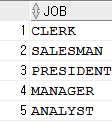
DISTINCT는 중복제거
- 칼럼에 연산자 쓸 수 있음
ex1)
SELECT ename, sal as 월급, sal * 12 AS 연봉 FROM emp;

ex2)
SELECT * FROM emp WHERE sal = 1600;

- 비교연산자
SELECT * FROM emp WHERE depno <> 30;
SELECT * FROM emp WHERE depno != 30;
SELECT * FROM emp WHERE depno ^= 30;
SELECT * FROM emp WHERE not depno = 30;다 같은 말 (depno 이 30이 아닌 값찾기)
- job이 salesmasn이고 comm이 300이상인 값찾기
SELECT * FROM emp WHERE job = 'SALESMAN' and comm >= 300;
- 이런식으로 괄호를 써서 연산을 할 수도 있음
SELECT * FROM emp
WHERE deptno = 20 AND (sal >= 2000 OR hiredate < '82/01/01');
- IN(값1, 값2) : 값이 1이거나 2거나
SELECT * FROM emp WHERE deptno IN(20,30);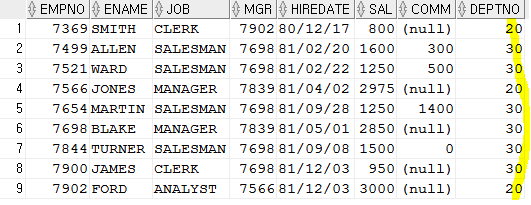
SELECT * FROM emp WHERE job IN('SALESMAN','CLERK');
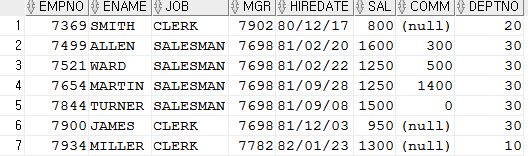
not in쓸수도 있음
SELECT * FROM emp WHERE job NOT IN('SALESMAN','CLERK');
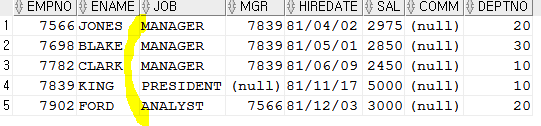
- between
SELECT * FROM emp WHERE empno BETWEEN 7698 and 7902;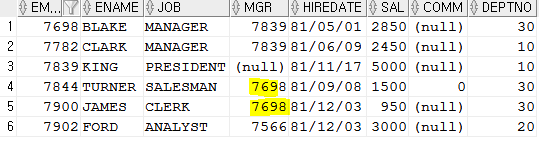
SELECT * FROM emp WHERE empno >=7698 and empno <=7902;이것과 결과값은 같다
1은 직관적이고 2는 개발자스럽다고한다이
- 와일드카드
SELECT * FROM emp WHERE ename LIKE 'AL%';
//AL로 시작하는 모든 이름
SELECT * FROM emp WHERE enma LIKE '%ON%';
//중간에 ON이 들어간 모든 이름- % (Percentage) : 0개 이상의 임의의 문자열을 의미한다.
- _ (Underscore) : 문자 1개를 의미한다.
LIKE는 잘못사용하면 속도가 느려지기때문에 유의
- IS NULL / IS NOT NULL
SELECT * FROM emp WHERE NOT comm IS NULL;
SELECT * FROM emp WHERE comm IS NOT NULL;결과값은 같음
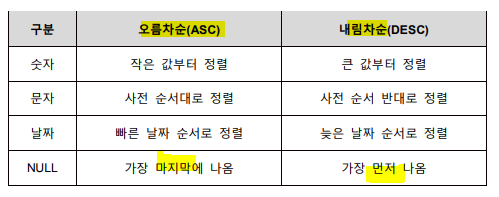
- order by (컬럼명 or 몇번쨰 칼럼)
디폴트는 ASC
SELECT ename, sal FROM emp ORDER BY sal DESC, ename DESC;sal먼저 정렬후 ename정렬
SELECT empno 사원번호, ename 사원명, sal 월급, hiredate 입사일
FROM emp
ORDER BY 월급 DESC, 사원명 ASC; 별칭을 기준으로도 정렬가능(직관적임)
- || 더하기연산자
SELECT ename || '''s JOB is ' || job as EMPLOYEE FROM emp;
#2
- dual테이블(가상 테이블)
SELECT 20 * 30 FROM dual;
MOD : 나머지값
SELECT mod(5,4) FROM dual;
ABS : 절댓값
SELECT -10, ABS(10) FROM dual;
ROUND : 반올림값
SELECT 3.141592, round(3.141592) FROM dual;
TRUNC 버림
SELECT 12.3456, TRUNC(12.3456), TRUNC(12.3456, 2),
TRUNC(12.3456, -1), TRUNC(12.3456, 0)
FROM dual; 
CEIL 인접한 가장 큰수 <-> FLOOR 인접한 가장 작은수
SELECT CEIL(12.3456) FROM dual;값 : 13
POWER(값1, 값2) : 값1의 값2승
SELECT power(2,3) FROM dual;2의 3승이니까 값은 8
- 문자함수
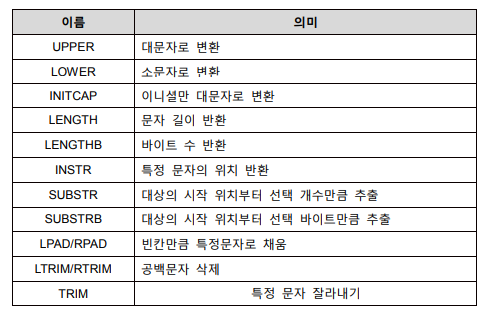
UPPER/LOWER
SELECT UPPER('sam') FROM dual;
SELECT LOWER(UPPER('sam')) FROM dual;
INITCAP : 이름표기할때 유용
SELECT INITCAP('kim mal ddong') FROM dual;
SELECT INITCAP(ename) FROM emp;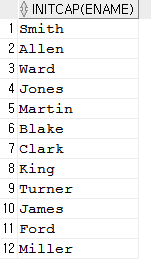
INSTR : 특정 문자의 위치 반환
SELECT INSTR('ORACLE=WELCOME', 'C') FROM dual;이 문자열에서 C가 어디에 위치해있는가?
결과값 : 4(처음에 있는값)
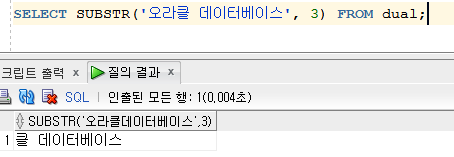
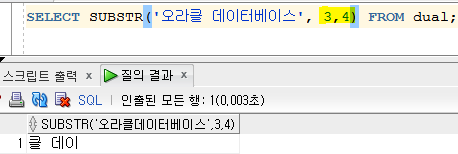
SUBSTR : 대상의 시작 위치부터 선택 개수만큼 추출
- ltrim/rtrim왼쪽 또는 오른쪽의 공백문자를 제거해주는 함수
SELECT
'ORACLE',
ltrim(' ORACLE'),
rtrim('ORACLE ')
FROM dual;
TRIM : 양끝 공백제거
SELECT TRIM('a' FROM 'aaaOracleaaa') FROM dual; 
TO_CHAR을 이용해 SYSDATE를 바꾸기
SELECT TO_CHAR(SYSDATE, ‘yyyy/mm/dd hh24:mi:ss’) FROM dual; 
add_months
SELECT add_months(sysdate, '2') FROM dual;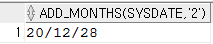
next_ day
SELECT next_day(sysdate, '금') from dual;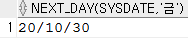
가장 가까이 있는 금요일반환
- nvl([값 or 컬럼,] 출력할 값)
SELECT ename, nvl(comm,0) comm FROM emp;
nvl2
SELECT ename, nvl2(comm, sal + comm, sal) as pay, sal, comm FROM emp;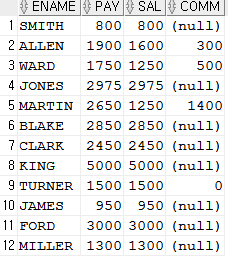
선호는 x
#3
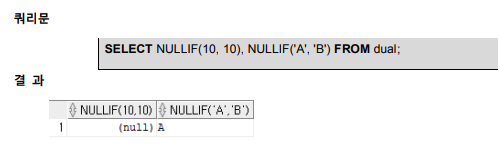
- nullif
두 값을 비교하여 동일한지 아닌지에 대한 결과 반환 두 값이 동일하면 NULL반환, 동일하지 않으면 첫 번째 값 반환
- DECODE
조건에 해당하는 값을 추출할 때 사용 조건이 TRUE일 경우와 FALSE일 경우 반환하는 값을 다르게 지정할 수 있으며 FALSE 부분을 연장하 여 복잡한 조건을 줄 수 있다
SELECT DECODE(100, 100, 'EQUAL', 'UNEQUAL') FROM dual;
SELECT DECODE(100, 150, 'EQUAL', 'UNEQUAL') FROM dual;
결과값은 EQUAL, UNEQUAL나옴
SELECT empno, ename, deptno,
DECODE(deptno, 10, '회계팀', 20, '개발팀', 30, '영업팀', 40, '운
영팀') deptname
FROM emp;deptno가 10이면 회계팀 20이면 개발팀 30이면 영업팀
첫번째만 칼럼이고 나머지는 값출력쌍을 표현
- CASE WHEN
SELECT
ename,
CASE
WHEN deptno = 10 THEN '회계팀'
WHEN deptno = 20 THEN '개발팀'
WHEN deptno = 30 THEN '영업팀'
WHEN deptno = 40 THEN '운영팀'
ELSE '팀없음'
END as team
FROM emp;
round를 사용하여 평균값의 소수n째자리 지정
SELECT ROUNd(avg(sal),2) FROm emp;
- group by
SELECT job, round (avg(sal)) as avgsal
FROM emp
GROUP by job
ORDER by avgsal asc;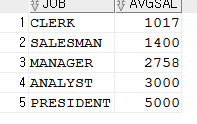
- Join
SELECT job, count(job) as 인원
FROM emp e
JOIN dept d
ON e.deptno = d.deptno
GROUP BY job
ORDER BY 인원 DESC;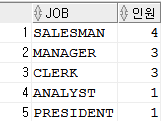
'DB > Oracle' 카테고리의 다른 글
| 20201029_24 순위, 누적, 집계, 조인 (0) | 2020.10.29 |
|---|---|
| 20201028_23 UPDATE, MERGE (0) | 2020.10.28 |
| 20201027_ 23 문제 및 해결2 (0) | 2020.10.27 |
| 20201026_22 문제 및 해결1 (0) | 2020.10.26 |
| 20201026_22 제약조건 (0) | 2020.10.26 |


댓글